low level Optimization of KFR
- Optimization of log(|| x – x0, y – y0||)
- Optimization of log function
- Optimization of fast atan
- Make the shader more complex to extend the rendering time to greater than 16ms
I will talk about every step in detail
- Optimization of log(|| x – x0, y – y0||)
- There is rendering time reduction
- Original 52.96ms
- 1/2 buffer: 15.39ms ->15.57ms
- 1/4 buffer: 4.20ms -> 4.10ms
- There is rendering time reduction
- Optimization of log function
- The fast-log contains at least 5 branches (possibly 5 additions and 5 shifts for 32 bit calculation)
- The Nvidia log algorithm is not available on line. But the log, exp, sin, cos in AMD GPU is 4x that of add/sub. We can guess Nvidia doesn’t do worse than AMD.
- Reference1: http://www.iquilezles.org/www/articles/palettes/palettes.htm (Iq talking about sin, cos in GLSL)
- Popular wisdom (especially between old-school coders) is that trigonometric functions are expensive and that therefore it is important to avoid them (by means of LUTs or linear/triangular approximations). Often popular wisdom is wrong – despite the above still holds true in some especial cases (a CPU heavy inner loop) it does not in general: for example, in the GPU, computing a cosine is way, way faster than any attempt to approximate it. So, lets take advantage of this and go with the straight cosine expression.
- Analysis of AMD GPU: https://seblagarde.wordpress.com/tag/gpu-performance/
- Full rate (FR): mul, mad, add, sub, and, or, bit shift… Quater rate(QR): transcendental instruction like rcp, sqrt, rsqrt, cos, sin, log, exp…
- Discussion about complexity of complexity:
- 1/x, sin(x), cos(x), log2(x), exp2(x), 1/sqrt(x) – 0 or close to 0, as long as they are limited to 1/9 of all total ops (can go up to 1/5 for Maxwell).
- Reference1: http://www.iquilezles.org/www/articles/palettes/palettes.htm (Iq talking about sin, cos in GLSL)
- Optimization of fast atan (I only tried diamond angle now. I will try the CORDIC later.)
- Simple comparison of atan2 and diamond angle.
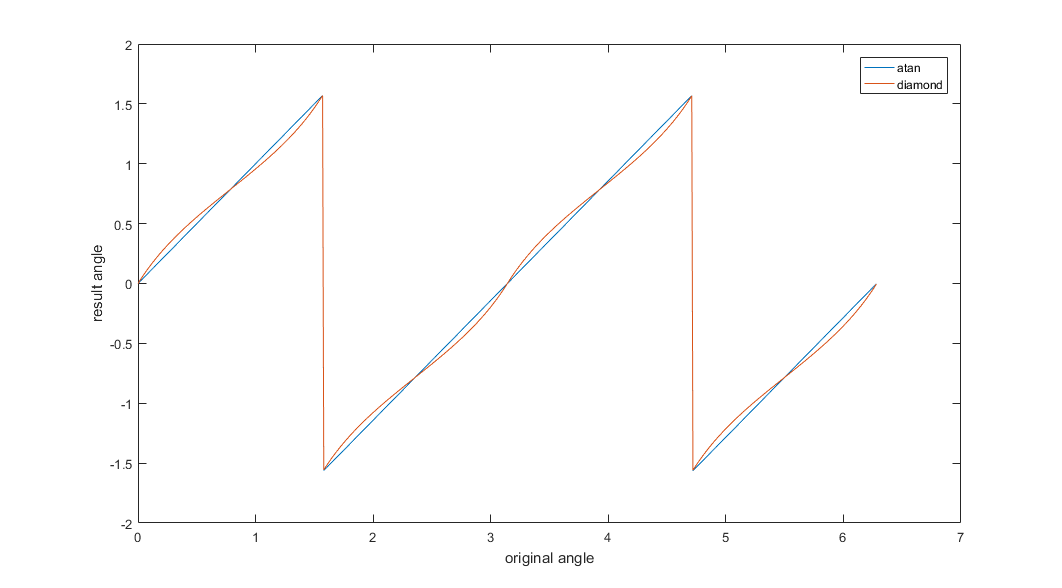
- A test of shadertoy: https://www.shadertoy.com/view/lllyR4
- Make the shader more complex to extend the rendering time to greater than 16ms
