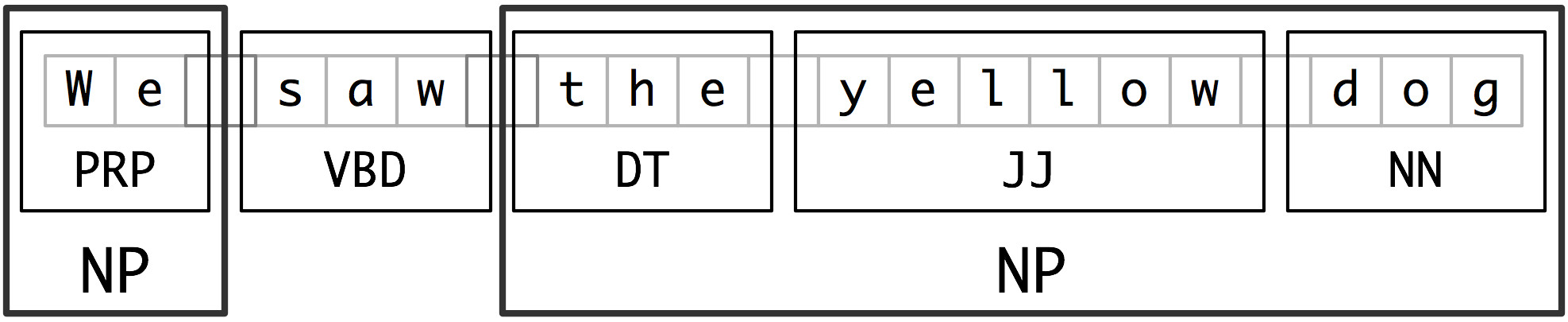
Questions:
- Generative Model P(X,Y)
- Discriminative model P(Y|X)
MainPoints
- Block sampler: Instead of sample one element at a time, we can sample a batch of samples in Gibbs Sampling.
- Lag and Burn-in: can be viewed as parameters (we can control the number of iterations)
- lag: mark some iterations in the loop as lag, then throw away the lag iterations, then the other samples become independent.
- Example: run 1000 iters -> run 100 lags -> run 1000 iters -> 100 lags …
- burn in: throw away the initial 10 or 20 iterations (burn-in iterations), where the model has not converged.
- The right way is to test whether the model has converged.
- Topic model:
- The sum of the parameter of each word in a topic doesn’t need to be one
- The derivative (branches) of LDA (Non-parametric model):
- Supervised LDA
- Chinese restaurant process (CRP)
- Hierarchy models
- example: SHLDA
- gun-safety (Clinton) & gun-control (Trump)
Parsing:
Any context which can be processed with FSA can be processed with CFGs. But not vice versa.
| ? |
turning machine |
|
|
(Don’t cover in this lecture) |
|
| CSL |
Tree adjusting Grammar |
PTAGs |
|
(Don’t cover in this lecture) |
|
| CF |
PDA/CFGs |
PCFGs |
|
PDA/CFGs Allow some negative examples. And can handle some cases that cannot be processed by FSA.
For example: S -> aSb {a^nb^n} cannot be processed by FSA because we need to know the variable n. But FSM only remember the states, it cannot count. |
|
| Regular |
FSA/regular expressions |
HMM |
Example1:
The rat that the cat that the dog bit chased died.
Example2:
Sentence: The tall man loves Mary.
————-loves
—–man————Mary
-The——tall
Structure:
——————-S
——–NP——————VP
—DT-Adj—N V——–NP
—the-tall–man loves—–Mary
Example3: CKY Algorithm
0 The 1 tall 2 man 3 loves 4 Mary 5
[w, i, j] A->w \in G
[A, i, j]
Chart (bottom up parsing algorithm):
0 The 1 tall 2 man 3 loves 4 Mary 5
–Det —— N ———V ——NP—-
———–NP ———–VP ———
—————- S ———————
Then I have:
[B, i, j]
[C, j, k]
So I can have:
A->BC : [A, i, k] # BC are non-determinal phrases
NP ->Det N
VP -> V NP
S -> NP VP
Example4:
I saw the man in the park with a telescope.
——————– NP—————– PP ———–
– —————NP———————
————————NP—————————–
A->B . CD
B: already
CD: predicted
[A -> a*ß, j]
[0, S’-> *S, 0]
scan: make progress through rules.
[i, A -> a* (w_j+1) ß, j]
A [the tall] B*C
i, [the tall], j
Prediction: top-down prediction B-> γ
[i, A-> a * Bß, j]
[j, B->*γ, j]
Combine
Complete (move the dot):
[i, A->a*ß, k] [k, B->γ, j]
I k j
–[A->a*Bß]———[B->γ*]—–
Then I have:
[I, A->aB*ß, k]
 w’s are observable
w’s are observable