Plan for tomorrow:
- try to download dependency of https://github.com/NCCA/Sponza
- if not work, try to load the textures
- Change from single float to short in for peripheral pixels
- finish homework for 726 in python
Plan for tomorrow:
low level Optimization of KFR
I will talk about every step in detail
Research:
8:30am – 11: 30am
3:00 pm – 6:00 pm
Tomorrow:
Leetcode:
Decouple shading rate & visibility rate from pixels: allow for space for anti-aliasing and coarse pixel shading.
Texel Shading (shading rate reduction):
We show performance improvements in three ways. First, we show some improvement for the “small triangle problem”. Second, we reuse shading results from previous frames. Third, we enable dynamic spatial shading rate choices, for further speedups.
Visibility: updating visibility at the full frame rate.
Shading rate: dynamically varying the spatial shading rate by simply biasing the mipmap level choice, texel shading and temporal shading reuse
Some reason for increased shading cost
Process: deferred decoupled shading
rasterization -> records texel accesses as shading work rather than running a shade per pixel. Shading is performed by a separate compute stage, storing the results in a texture. A final stage collects data from the texture
Object Space Lighting:
Inspired by REYES (render everything your eyes can see)
Overall process
All objects in game are submitted for shading and rasterization. Queued for process
During submission step, the estimated projected area of the object is calculated. Thus an object requests a certain amount of shading
During shading, system allocates texture space for all objects which require shading. If the total request is more then available shading space, all objects are progressively scaled at shading rate until it fits
Material shading occurs, processing each material layer for each object. Results are accumulated into the master shading texture(s)
MIPS are calculated on master shading texture as appropriate
Rasterization step: each object references the shading part step. No specific need that there is a 1:1 correspondence, but this feature is rarely used.
AMFS:
Our architecture is also the first to support pixel shading at multiple different rates, unrestricted by the tessellation or visibility sampling rates.
automatic shading reuse between triangles in tessellated primitives
enables a wider use of tessellation and fine geometry, even at very limited power budgets

3 BUFFERS in OpenGL
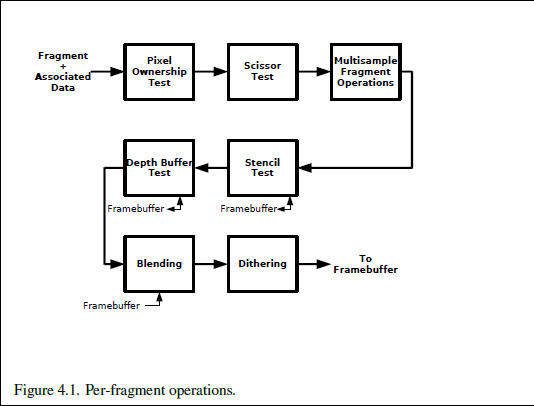
Do MSAA in GLFW: http://blog.csdn.net/column/details/14890.html
Research:
As we discussed last week, to make our paper better, we should:
To make our algorithm better than others, what I did last week is:


To compare with work of others, I need to redo the work of others.
I have already implemented the work of Microsoft without blur.
Built a summary for the
Next week:
Implement code of nvidia paper.
A similar apporach: https://github.com/GameTechDev/DeferredCoarsePixelShading
Microsoft code:
https://www.microsoft.com/en-us/download/details.aspx?id=52390
Write the summary paper.
Today:
Deferred shading is a screen-space shading technique. It is called deferred because no shading is actually performed in the first pass of the vertex and pixel shaders: instead shading is “deferred” until a second pass.
Decoupled shading: shades fragments rather than micropolygons vertices. Only shades fragments after precise computation of visibility.
Visibility: how much we read from the primitives
Shading rate: how much we render.
🙁
Research: