- sequence classification
- sequence prediction
- seq2seq(https://www.csdn.net/article/2015-08-28/2825569)
- Input: sentence
- Output: sentence
- pinput -> intermediate state -> output (see the reference)
- encoder:
- decoder:
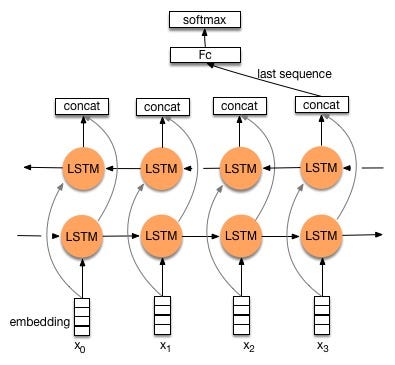
- Bidirectional LSTM
|
1 2 3 4 5 6 7 |
for (int i = 0; i < 16; i++) { for (int j = 0; j < 16; j++) { ... tmpColor = texture(texSampler, vec3(pixel.xy,i * DIM + j)); ... } } |
|
1 2 3 4 5 6 7 |
for (int i = 0; i < 16; i++) { for (int j = 0; j < 16; j++) { ... tmpColor = UNITY_SAMPLE_TEX2DARRAY(_ArrTex, float3(pixel.xy, (15 - j) * DIM + i)); ... } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
void CreateTex2DArray() { int TotalTexNum = texDim * texDim; mainTexture = new Texture2DArray(width, height, TotalTexNum, TextureFormat.RGB24, false); mainTexture.filterMode = FilterMode.Point; mainTexture.wrapMode = TextureWrapMode.Clamp; string badName = "invalid_texture"; Texture2D badTex = Resources.Load(badName) as Texture2D; if (badTex == null) { Debug.Log(badName + " not found."); } for (int i = 0; i < TotalTexNum; i++) { //string fileName = "test/test" + i.ToString(); int firstIdx = i % texDim; int secondIdx = i / texDim; string fileName = "lytro/out_" + firstIdx.ToString("D2") +"_"+ secondIdx.ToString("D2"); Texture2D smallTex = Resources.Load(fileName) as Texture2D; if (smallTex == null) { Debug.Log(fileName + " not found."); mainTexture.SetPixels(badTex.GetPixels(), i, 0); } else { mainTexture.SetPixels(smallTex.GetPixels(), i, 0); } } mainTexture.Apply(); } |
Collection of all pre-trained Word2Vec Models:
http://ahogrammer.com/2017/01/20/the-list-of-pretrained-word-embeddings/
Google’s model seems not reliable…
Here are some similarity tests of Google’s model:
The similarity between good and great is: 0.7291509541564205
The similarity between good and awesome is: 0.5240075080190216
The similarity between good and best is: 0.5467195232933185
The similarity between good and better is: 0.6120728804252082
The similarity between great and awesome is: 0.6510506701964475
The similarity between great and best is: 0.5216033921316416
The similarity between great and better is: 0.43074460922502006
The similarity between awesome and best is: 0.3584938663818339
The similarity between awesome and better is: 0.27186951236001483
The similarity between best and better is: 0.5226434484898708
The similarity between food and foodie is: 0.3837408842876883
The similarity between food and eat is: 0.5037572298482941
The similarity between foodie and eat is: 0.3050075692941569
The similarity between park and view is: 0.1288395798972001
The similarity between design and art is: 0.3347430713890944
Questions:
MainPoints
Parsing:
Any context which can be processed with FSA can be processed with CFGs. But not vice versa.
| ? | turning machine | |
| (Don’t cover in this lecture) | ||
| CSL | Tree adjusting Grammar | PTAGs |
| (Don’t cover in this lecture) | ||
| CF | PDA/CFGs | PCFGs |
| PDA/CFGs Allow some negative examples. And can handle some cases that cannot be processed by FSA.
For example: S -> aSb {a^nb^n} cannot be processed by FSA because we need to know the variable n. But FSM only remember the states, it cannot count. |
||
| Regular | FSA/regular expressions | HMM |
Example1:
The rat that the cat that the dog bit chased died.
Example2:
Sentence: The tall man loves Mary.
————-loves
—–man————Mary
-The——tall
Structure:
——————-S
——–NP——————VP
—DT-Adj—N V——–NP
—the-tall–man loves—–Mary
Example3: CKY Algorithm
0 The 1 tall 2 man 3 loves 4 Mary 5
[w, i, j] A->w \in G
[A, i, j]
Chart (bottom up parsing algorithm):
0 The 1 tall 2 man 3 loves 4 Mary 5
–Det —— N ———V ——NP—-
———–NP ———–VP ———
—————- S ———————
Then I have:
[B, i, j]
[C, j, k]
So I can have:
A->BC : [A, i, k] # BC are non-determinal phrases
NP ->Det N
VP -> V NP
S -> NP VP
Example4:
I saw the man in the park with a telescope.
——————– NP—————– PP ———–
– —————NP———————
————————NP—————————–
A->B . CD
B: already
CD: predicted
[A -> a*ß, j]
[0, S’-> *S, 0]
scan: make progress through rules.
[i, A -> a* (w_j+1) ß, j]
A [the tall] B*C
i, [the tall], j
Prediction: top-down prediction B-> γ
[i, A-> a * Bß, j]
[j, B->*γ, j]
Combine
Complete (move the dot):
[i, A->a*ß, k] [k, B->γ, j]
I k j
–[A->a*Bß]———[B->γ*]—–
Then I have:
[I, A->aB*ß, k]
 w’s are observable
w’s are observable
https://www.wordclouds.com/
GLuint posLength = sizeof(PointStruct) * PointCloudData.size(); correct
GLuint posLength = sizeof(PointCloudData) ; wrong
glBufferData(GL_ARRAY_BUFFER, posLength, &PointCloudData[0], GL_STATIC_DRAW);
| Units | Prob | |
| String | {anbn|n>=1} | P(w1, w2,…, wn) |
| Structure | A tree structure | PCFG |
| G1 | G2 |
| S->a s | s->s a |
| s->e | s->e |

