The results are obvious in 1135, 1124, 1113
Month: March 2018
Questions about “Foveated 3D Graphics (Microsoft)” User Study
- Problem1: They did test for only one scene.
- The first problem is that foveation level is highly depentent on scene. They may get totally different parameters if they change to another scene. Of course, this is the problem of all the user studies. Till now, only NVIDIA mentiond the multliple factors affecting vision. However, they don’t have good ways to deal with this.
- The second problem is about data analysis. They avoid the problem of one parameter ->multiple result by testing only one scene.
- Problem2: I don’t believe that their result is monotone.
- They just said:
- Ramp Test: For the ramp test, we identified this threshold as the lowest quality index for which each subject incorrectly labeled the ramp direction or reported that quality did not change over the ramp.
-
Pair Test: for the pair test, we identified a foveation quality threshold for each subject as the lowest variable index jhe or she reported as equal to or better in quality than the non-foveated reference.
- Suppose their quality level is 11,12,13,14,15. What if they get result of 1,1,1,0,1 ? Is their final quality level 13 or 15?
- I don’t believe this situation did happen in their user study.
- If it happens, what should we do? Of course we should test for multiple scenes for many participants, and get the average. So we go back to problem 1.
- They just said:
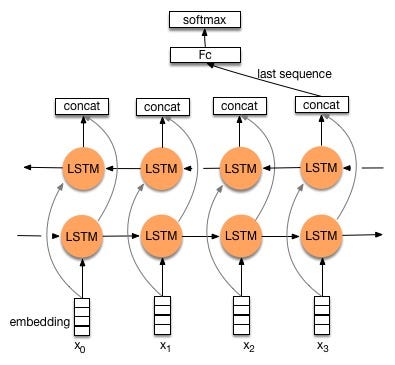
Lecture 8: sequence classification
- sequence classification
- sequence prediction
- seq2seq(https://www.csdn.net/article/2015-08-28/2825569)
- Input: sentence
- Output: sentence
- pinput -> intermediate state -> output (see the reference)
- encoder:
- decoder:
- Bidirectional LSTM
The key of using Unity Texture array
- The texture array structure in different from GLSL and Unity + HLSL, the sequence of image index i and j must be adjusted. Suppose the light field has structure 16 x 16:
-
- In GLSL Shader:
1234567for (int i = 0; i < 16; i++) {for (int j = 0; j < 16; j++) {...tmpColor = texture(texSampler, vec3(pixel.xy,i * DIM + j));...}}-
- In Unity Shader:
1234567for (int i = 0; i < 16; i++) {for (int j = 0; j < 16; j++) {...tmpColor = UNITY_SAMPLE_TEX2DARRAY(_ArrTex, float3(pixel.xy, (15 - j) * DIM + i));...}} -
- The program of using texture array in unity
- Suppose we want to load the images in folder “lytro”, we must mkdir called “Resources” in the folder “Asset”, then drag the folder “lytro” into “Resources”.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
void CreateTex2DArray() { int TotalTexNum = texDim * texDim; mainTexture = new Texture2DArray(width, height, TotalTexNum, TextureFormat.RGB24, false); mainTexture.filterMode = FilterMode.Point; mainTexture.wrapMode = TextureWrapMode.Clamp; string badName = "invalid_texture"; Texture2D badTex = Resources.Load(badName) as Texture2D; if (badTex == null) { Debug.Log(badName + " not found."); } for (int i = 0; i < TotalTexNum; i++) { //string fileName = "test/test" + i.ToString(); int firstIdx = i % texDim; int secondIdx = i / texDim; string fileName = "lytro/out_" + firstIdx.ToString("D2") +"_"+ secondIdx.ToString("D2"); Texture2D smallTex = Resources.Load(fileName) as Texture2D; if (smallTex == null) { Debug.Log(fileName + " not found."); mainTexture.SetPixels(badTex.GetPixels(), i, 0); } else { mainTexture.SetPixels(smallTex.GetPixels(), i, 0); } } mainTexture.Apply(); } |
Word2Vec Models
Collection of all pre-trained Word2Vec Models:
http://ahogrammer.com/2017/01/20/the-list-of-pretrained-word-embeddings/
Google’s model seems not reliable…
Here are some similarity tests of Google’s model:
The similarity between good and great is: 0.7291509541564205
The similarity between good and awesome is: 0.5240075080190216
The similarity between good and best is: 0.5467195232933185
The similarity between good and better is: 0.6120728804252082
The similarity between great and awesome is: 0.6510506701964475
The similarity between great and best is: 0.5216033921316416
The similarity between great and better is: 0.43074460922502006
The similarity between awesome and best is: 0.3584938663818339
The similarity between awesome and better is: 0.27186951236001483
The similarity between best and better is: 0.5226434484898708
The similarity between food and foodie is: 0.3837408842876883
The similarity between food and eat is: 0.5037572298482941
The similarity between foodie and eat is: 0.3050075692941569
The similarity between park and view is: 0.1288395798972001
The similarity between design and art is: 0.3347430713890944
Lecture 8: Evaluation
- Information about midterm
- PCFG
- Start with S
- ∑Pr(A -> gamma | A) = 1
- (conditional) probability of each item has to sum to one
- Pr(O = o1,o2,…,on|µ)
- HMM: Forward
- PCFG: Inside-Outside
- Guess Pr: argmax_(Z)[ Pr(Z|O, µ) ]
- HMM:Use Viterbi to get
- PCFG: Use Viterbi CKY to get
- *Z is the best sequence of states
- Guess µ: argmax_(µ)[Pr(O|µ)]
- HMM:Use forward-backward to get
- PCFG: Use Inside-outside to get
- Example:
- Sentence:
- ——————-S
- ——–NP—————-VP
- ——–NP———-V————-NP
- ——people——eats —–adj——–N
- —————————roasted—-peanuts
- Problem:
- Pr_µ(peanuts eat roasted people) = Pr_µ(people eat roasted peanut)
- We can try to generate head of each phrase:
- ————————————S (Head: eat)
- ——–NP(Head: people)—————————–VP(Head: eat)
- ——–NP(Head: people)———-V(Head: eat)——————————–NP(Head: peanut)
- ——people(Head: people)——eats(Head: eat)————-adj(Head: N/A)—————–N(Head: peanut)
- —————————————————————–roasted(Head: N/A)————-peanuts(Head: peanut)
- Should have: Pr[S (Head: eat) -> NP(Head: people) VP(Head: eat)] > Pr[ S (Head: eat) -> NP(Head: peanut) VP(Head: eat) ]
- Sentence:
- Dependency representation:
- Sentence:
- —————————eat
- —————people—————peanuts
- —————–the—————–roasted
- Lexical (bottom up)
- NP ->det N
- Sentence:
- Evaluation
- Reference Reading:How Evaluation Guides AI Research
- Intrinsic evaluation
- Extrinsic evaluation
- Kappa’s evaluation
- Metric: precision recall
- How to evaluate two structures which could generate the same sentence?
- Answer: Generate more than one output for each input, convert the output into set of output, and use precision and recall to measure.
- Reader evaluation:
- If the reader’s score agree with the machine, stop
- else: let another reader read the essay
- Reference Reading:How Evaluation Guides AI Research
03102018
- Gensim Tutorial:
- https://radimrehurek.com/gensim/models/word2vec.html
- Use google-news model as pre-trained model
- clustering based on distance matrix
- Question: how do we do the clustering?
- should cluster on the keywords?
- should cluster on the keywords-related words?
- Leg dissection demo:
- 18 cameras 30frames 10G
- 5 cameras 100 frames 6G
- Question:
- what is our task?
- we cannot change focal length now. we can only change the viewpoint
- if we want dynamic, we should have dynamic mesh?
- what is our task?
- Foveated ray-tracing:
- input: eye ray + 1spp
- output: foveated image
- question: If we use foveated image as ground truth, what should be the denoising algorithm for the ground truth?
- TODO:
- read G3D code and change sample number
- read papers (nvd, disney)
- Homework
Lecture 6: Context-free parsing
Questions:
- Generative Model P(X,Y)
- Discriminative model P(Y|X)
MainPoints
- Block sampler: Instead of sample one element at a time, we can sample a batch of samples in Gibbs Sampling.
- Lag and Burn-in: can be viewed as parameters (we can control the number of iterations)
- lag: mark some iterations in the loop as lag, then throw away the lag iterations, then the other samples become independent.
- Example: run 1000 iters -> run 100 lags -> run 1000 iters -> 100 lags …
- burn in: throw away the initial 10 or 20 iterations (burn-in iterations), where the model has not converged.
- The right way is to test whether the model has converged.
- lag: mark some iterations in the loop as lag, then throw away the lag iterations, then the other samples become independent.
- Topic model:
- The sum of the parameter of each word in a topic doesn’t need to be one
- The derivative (branches) of LDA (Non-parametric model):
- Supervised LDA
- Chinese restaurant process (CRP)
- Hierarchy models
- example: SHLDA
- gun-safety (Clinton) & gun-control (Trump)
Parsing:
Any context which can be processed with FSA can be processed with CFGs. But not vice versa.
| ? | turning machine | |
| (Don’t cover in this lecture) | ||
| CSL | Tree adjusting Grammar | PTAGs |
| (Don’t cover in this lecture) | ||
| CF | PDA/CFGs | PCFGs |
| PDA/CFGs Allow some negative examples. And can handle some cases that cannot be processed by FSA.
For example: S -> aSb {a^nb^n} cannot be processed by FSA because we need to know the variable n. But FSM only remember the states, it cannot count. |
||
| Regular | FSA/regular expressions | HMM |
Example1:
The rat that the cat that the dog bit chased died.
Example2:
Sentence: The tall man loves Mary.
————-loves
—–man————Mary
-The——tall
Structure:
——————-S
——–NP——————VP
—DT-Adj—N V——–NP
—the-tall–man loves—–Mary
Example3: CKY Algorithm
0 The 1 tall 2 man 3 loves 4 Mary 5
[w, i, j] A->w \in G
[A, i, j]
Chart (bottom up parsing algorithm):
0 The 1 tall 2 man 3 loves 4 Mary 5
–Det —— N ———V ——NP—-
———–NP ———–VP ———
—————- S ———————
Then I have:
[B, i, j]
[C, j, k]
So I can have:
A->BC : [A, i, k] # BC are non-determinal phrases
NP ->Det N
VP -> V NP
S -> NP VP
Example4:
I saw the man in the park with a telescope.
——————– NP—————– PP ———–
– —————NP———————
————————NP—————————–
A->B . CD
B: already
CD: predicted
[A -> a*ß, j]
[0, S’-> *S, 0]
scan: make progress through rules.
[i, A -> a* (w_j+1) ß, j]
A [the tall] B*C
i, [the tall], j
Prediction: top-down prediction B-> γ
[i, A-> a * Bß, j]
[j, B->*γ, j]
Combine
Complete (move the dot):
[i, A->a*ß, k] [k, B->γ, j]
I k j
–[A->a*Bß]———[B->γ*]—–
Then I have:
[I, A->aB*ß, k]